



AMD Radeon HD 6970/6950显卡评测
Radeon HD 6970/6950图形技术解读
从4D+1D到4D:深入理解AMD 4D架构
Radeon HD 6970/6950为重要的改变就是从传统的4D+1D架构转变为4D架构,那么这样转变后的好处在哪里?AMD为什么要作出这样的调整?竞争对手NVIDIA又采用的是什么架构呢?
4D+1D架构的不足
AMD显卡传统的4D+1D结构可以在每次计算中处理一个像素的所有色彩或者坐标信息,不过考虑到有时候还需要一些特殊计算,比如sin、cos等,AMD还特别设计了一个ALU单元,称之为ALU.trans。这个特殊的单元和传统的用于计算四个ALU组成了AMD的4D+1D架构。
从理论上来看,4D+1D架构的效能是非常出色的。因为它一次计算就能处理一个像素所有的色彩或者坐标信息。但现实和理想总是有差距的,像素点并不是总需要计算位置或者色彩。一些像素实际上只需要改变色彩,坐标不变,或者只是运动一下,色彩信息没有变化,亦或者只是色彩中的某个数据需要计算,其他的不需要。总之,在实际计算中,并不是所有的信息都需要计算,这就造成了4D+1D架构中的部分单元的闲置。在严重的情况下,4D+1D架构在遇到全部由1D组成的计算需求时,性能只有理论值的1/5。
AMD工程师很早就在思考解决上述问题的办法,在R600以及后续的4D+1D计算中,AMD开始允许指令合并,也就是说几个不同的指令可以合并在一起进入流处理单元并进行计算。这样可以在部分场景下提升显卡的性能。比如说,两个2D指令接踵而来,传统计算是先计算一个2D,再计算另外一个2D,这样4D+1D架构的性能只有理论性能的40%,但一些新的设计可以允许这两个2D指令合并成一次计算,变成2D+2D,这样就能发挥80%的性能。与此类似的还有3D+1D、1D+1D+1D+1D+1D、1D+4D等特殊的复杂计算。
虽然AMD利用了种种手段对4D+1D架构进行了优化,但改进的4D+1D架构的效率还是不够理想,在很多情况下部分晶体管都在打瞌睡。AMD的SIMD架构虽然效率不一定高,但好处是规模扩充相当容易,比如AMD的4D+1D流处理单元作为一个整体,只需要一个指令发射端就可以解决问题。Cypress拥有1600个流处理算数单元,320个指令发射端就可以了。但NVIDIA的MIMD 1D架构,每个ALU都需要发射端等辅助设计,晶体管开销巨大。再加上缓存、线程调度器、寄存器等周边设计,1D架构在芯片体积和规模上都有比较明显的劣势。这也是造成NVIDIA DircetX 11显卡功耗较高的一个主要原因。
放弃4D+1D,转向4D
从RV670开始,AMD一直奉行小核心策略,在一定程度上避开了工艺难度问题。但为了保证不错的性能,对晶体管效率就必须有很高要求。因此,AMD在研发了很长一段时间的SIMD架构后,掌握了大量显卡计算中的信息和数据,认为继续保持这样的4D+1D结构对晶体管利用率的提升已经没有太大帮助了。因此,AMD在新的Cayman中,将4D+1D改进为4D结构,抛弃了之前的1D。
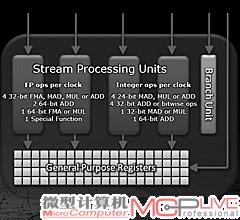
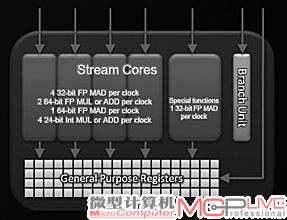
在4D(左)和4D+1D(右)架构下,一个SPU在一个时钟周期内可以完成的浮点计算和整数计算性能的对比。
AMD放弃的1D,是一个体积比较大的、用于一些特殊计算的ALU.trans(NVIDIA称之为SFU)。在放弃这个单元后,AMD重新设计了Cayman剩余的4D,将这四个4D单元变为对等的四个ALU。不仅如此,这四个ALU通过“合纵连横”,接管了之前ALU.trans的计算任务,比如一些特殊计算,可能需要占用3个ALU,但考虑到4D+1D本身就不太高的效率,这样的取舍从理论上来说是可能提升晶体管利用率的。根据AMD给出的数据,在改变成4D结构后,整个单元的每平方毫米性能可以提升10%。
不过效率的提升代价也相当明显。以定位相同的Radeon HD 5870为例,其具备1600个流处理算数逻辑单元(SPU),需要320个指令发射端(Radeon HD 5870是4D+1D架构,5D×320)。而Radeon HD 6970具备1536个流处理算数逻辑单元,SPU数量减少了,但指令发射端数量却增加到了384个(4D×384)。再加上周边一些辅助单元,整个晶体管规模就变得更为庞大。现在的Cayman晶体管数量达到了26.4亿,相比之前的Cypress的21.5亿提升了约23%,当然功耗也会随之提升。

